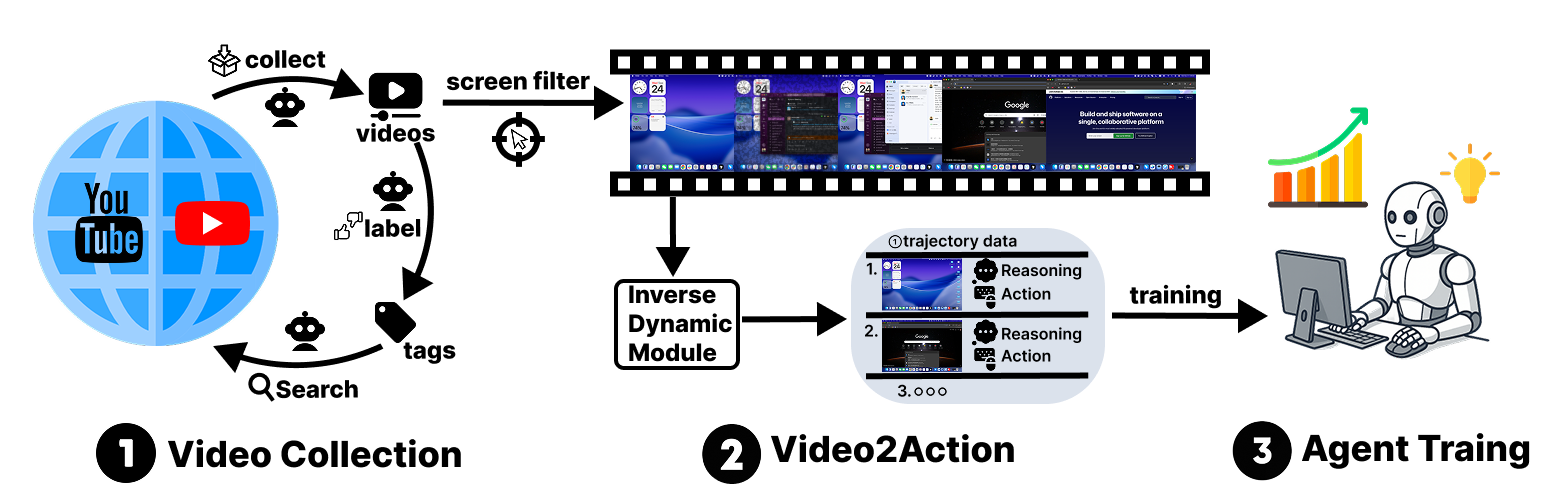
VideoAgentTrek is a video-driven pretraining pipeline for computer-use agents that turns in-the-wild screen-recorded tutorials into structured action trajectories—no manual annotation required. It detects GUI events directly from pixels, reconstructs parameters like click coordinates and typed text, and then trains agents with a two-stage recipe (video pretraining → supervised finetuning) to generalize across real apps and OSes.
Key Features & Contributions
See how Video2Action recovers detailed agent trajectories from raw screen-recorded videos—no manual annotation required 🧩
Raw screen-recorded video from YouTube tutorial
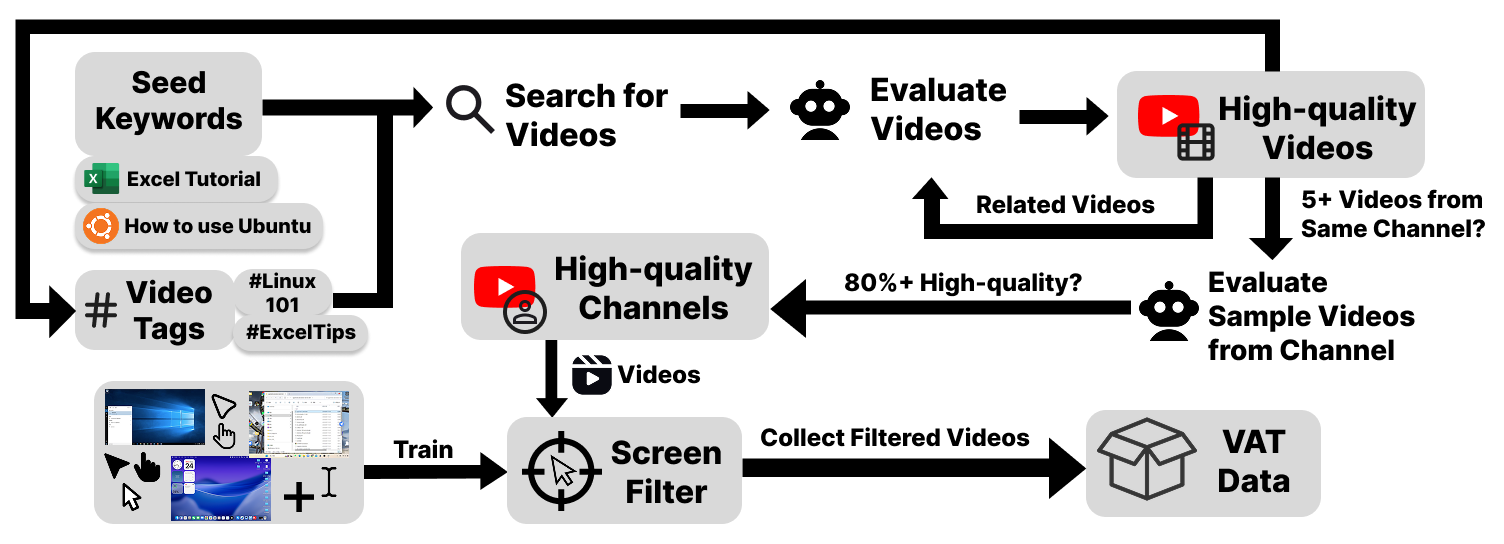
We build a scalable, channel-centric pipeline that grows from a handful of seed keywords (e.g., "Excel tutorial", "How to use Windows") into a large, high-quality corpus. Guided by channel coherence—the tendency of a channel to maintain stable topics and quality—we first validate a few seed videos; if ≥80% pass, we promote the entire channel as a trusted source and expand via its related videos, tags, and metadata. This recall-oriented discovery yields 55,000 candidate videos (~10,000 hours) with minimal human oversight.
To turn candidates into training-ready material, we apply ScreenFilter, a lightweight cursor-centric preprocessor (YOLOv8x backbone) that keeps only segments with sustained GUI interaction. Specifically, we retain clips where ≥80% of frames contain a cursor for at least 6s, with a 2s merge gap for temporal smoothing. Applied to our pool, ScreenFilter preserves 7,377 hours of verified GUI interaction from ~10,000 raw hours.
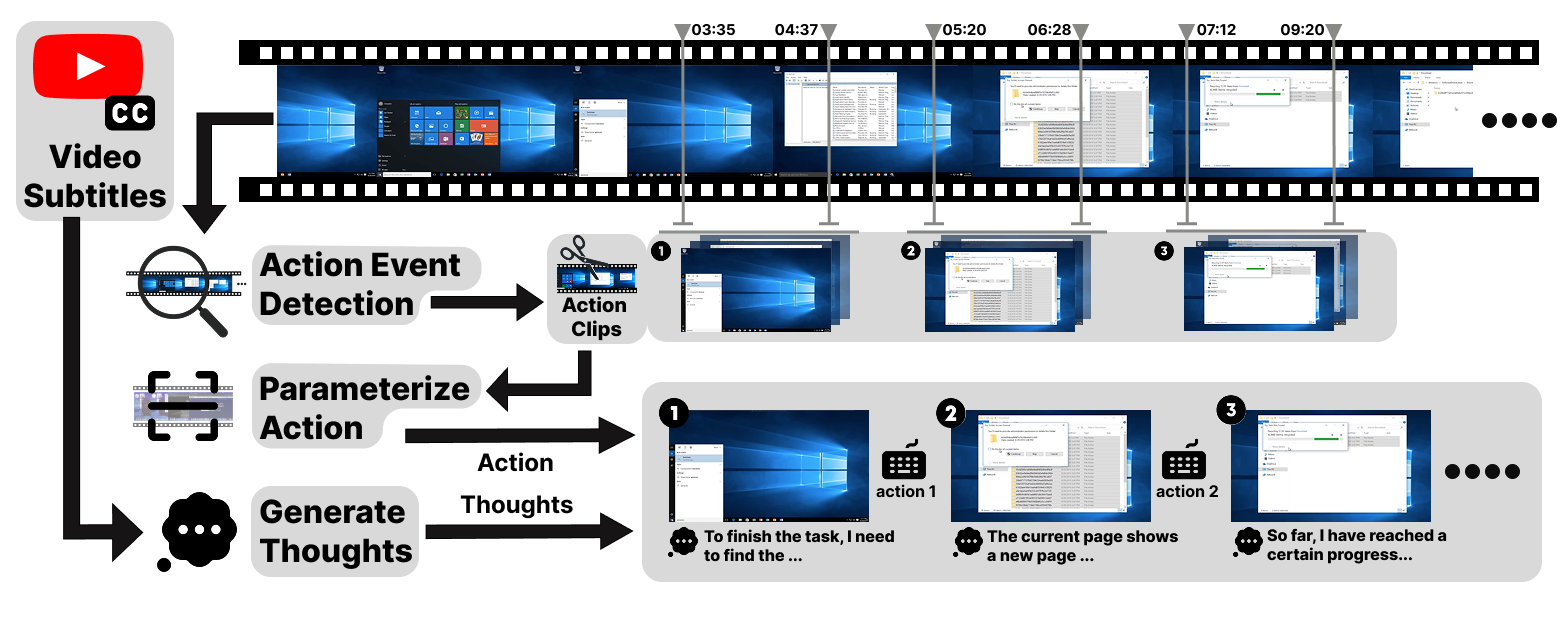
Video2Action recovers detailed agent trajectories from raw screen videos, without prompts or manual labels. It (i) performs dense GUI action event detection with tight temporal bounds, (ii) parameterizes each action from pixels (e.g., click (x,y), drag path, scroll Δ, typed text), and (iii) generates step-level thoughts that capture intent and expected state change. Trained with synchronized video–event logs and a grounded VLM, Video2Action converts in-the-wild tutorials into training-ready sequences {clip, action(type, params), thought}, forming the second core component of VideoAgentTrek.
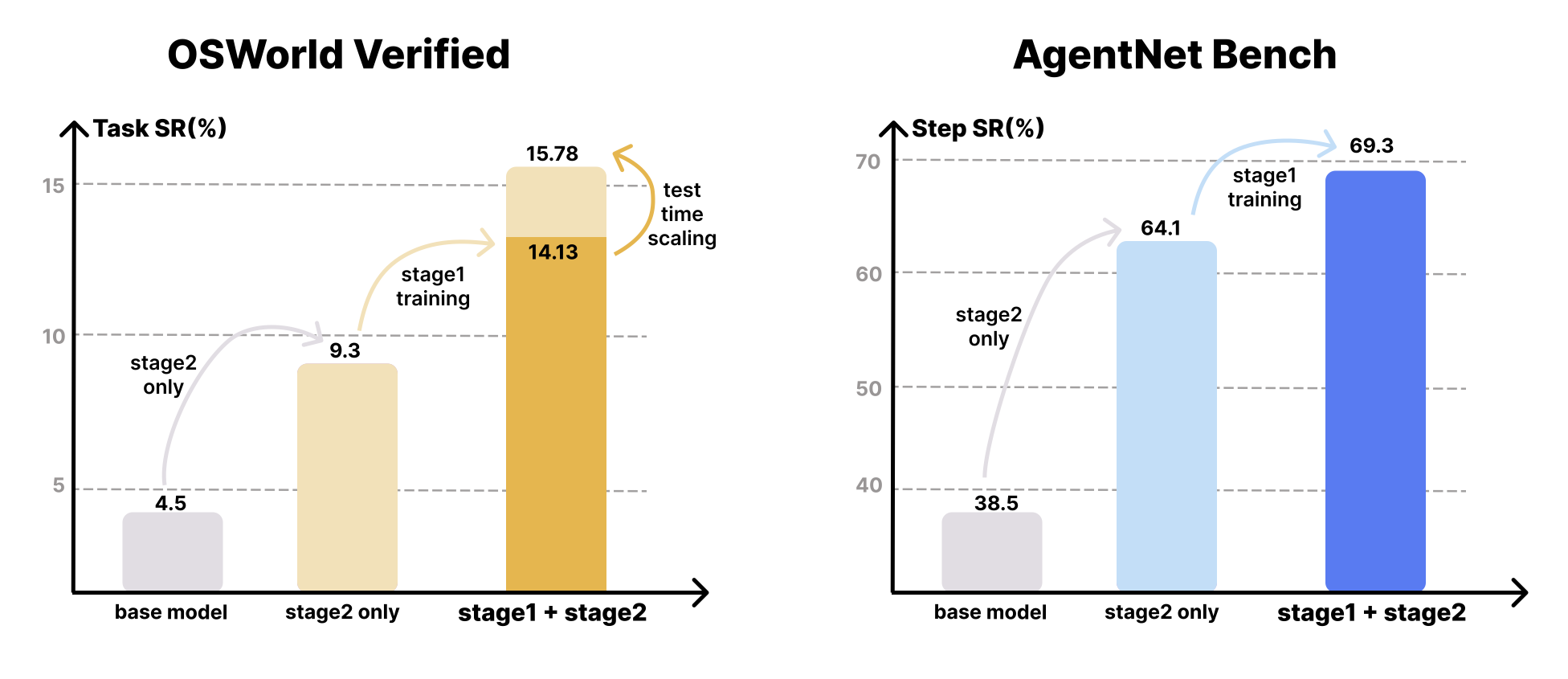
We train an end-to-end computer-use agent with a two-stage schedule over our video-mined trajectories and a clean SFT set. Stage 1 performs continued pretraining on 26B tokens from VideoAgentTrek (39k videos → 1.52M ReAct steps), interleaving frames with stepwise text and masking loss to text only. Stage 2 consolidates policy with 8B tokens of curated human demonstrations (chat-style SFT), while a focused GUI-grounding subset (~1B tokens) sharpens pointer–target alignment. This decoupled grounding→policy recipe lifts both offline and online performance: on OSWorld-Verified the base model (4.5%) improves to 9.3% with Stage 2 only and to 14.13% (up to 15.78% with test-time scaling) after Stage 1+2; on AgentNetBench, step accuracy rises from 38.5% (base) to 64.1% (Stage 2) and 69.3% (Stage 1+2).
We thank Fan Zhou, Tianbao Xie, and the anonymous reviewers for their insightful discussions and valuable feedback. We also sincerely appreciate Alibaba Qwen Team for their strong infrastructure support and helpful guidance. This paper’s authors received support from the ECS (27212023) provided by the RGC of HongKong.
If you find this work useful, please consider citing our paper:
@misc{lu2025videoagenttrekcomputerusepretraining,
title={VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos},
author={Dunjie Lu and Yiheng Xu and Junli Wang and Haoyuan Wu and Xinyuan Wang and Zekun Wang and Junlin Yang and Hongjin Su and Jixuan Chen and Junda Chen and Yuchen Mao and Jingren Zhou and Junyang Lin and Binyuan Hui and Tao Yu},
year={2025},
eprint={2510.19488},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.19488},
}